
实例介绍
【实例简介】
可以大批量爬取微博数据,用于进行数据分析
【实例截图】
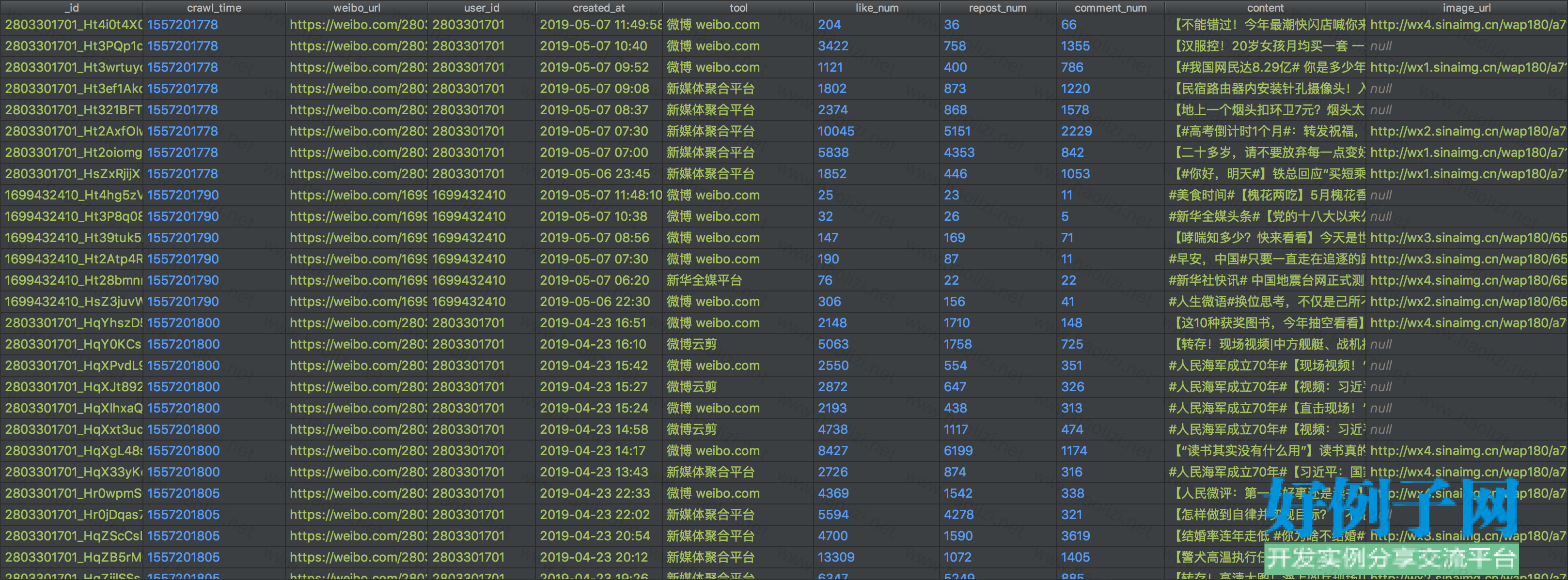
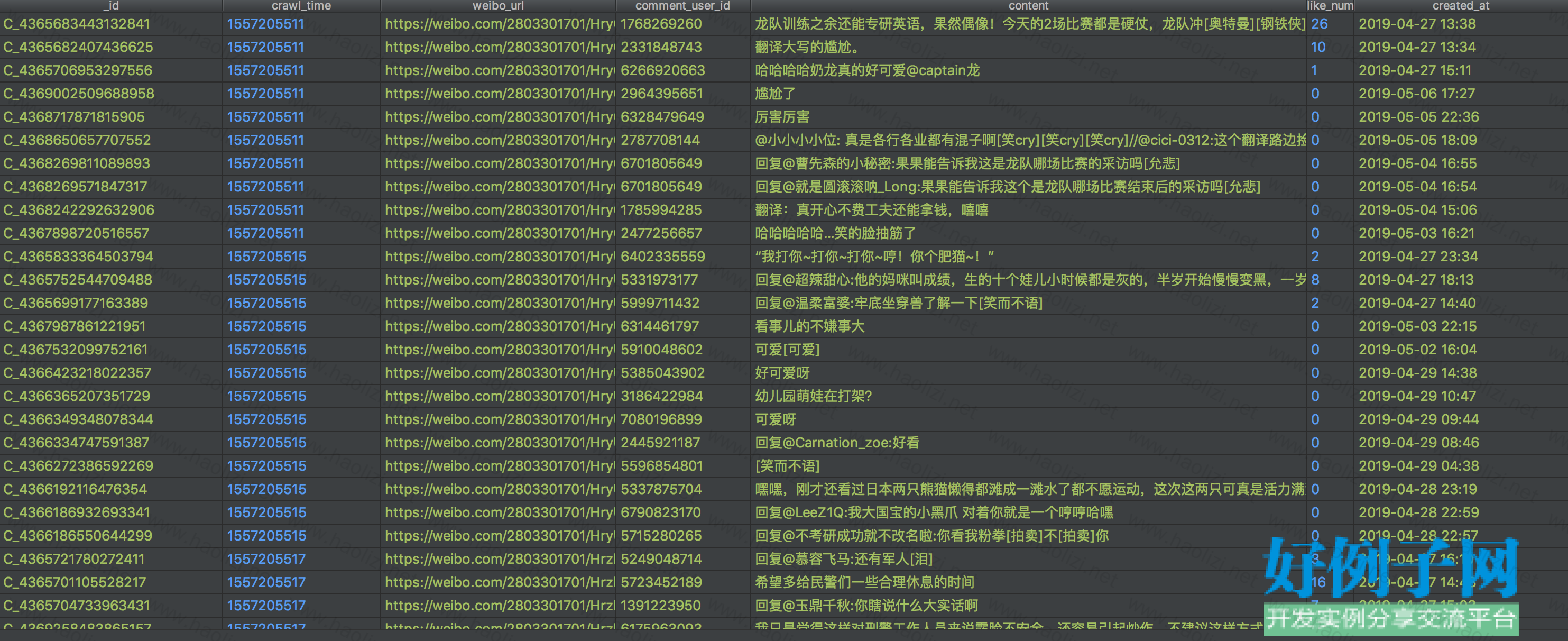
【核心代码】
#!/usr/bin/env python
# encoding: utf-8
import re
from lxml import etree
from scrapy import Spider
from scrapy.crawler import CrawlerProcess
from scrapy.selector import Selector
from scrapy.http import Request
from scrapy.utils.project import get_project_settings
from sina.items import TweetsItem, InformationItem, RelationshipsItem, CommentItem
from sina.spiders.utils import time_fix, extract_weibo_content, extract_comment_content
import time
#import html
class WeiboSpider(Spider):
name = "weibo_spider"
base_url = "https://weibo.com"
def start_requests(self):
start_uids = [
"1" #
#"2" #
# '2803301701', # 人民日报
# '1699432410' # 新华社
]
for uid in start_uids:
yield Request(url="https://weibo.com/p/1001018008642010000000000/relateweibo?feed_filter=filter&feed_sort=filter¤t_page=3&since_id=&page=%s" % uid, callback=self.response,
priority=1)
#yield Request(url="https://weibo.cn/%s/info" % uid, callback=self.parse_information)
def parse_tweet_addr(self, response):
# if response.url.endswith('page=1'):
# #如果是第1页,一次性获取后面的所有页
# all_page = 23 #re.search(r'/> 1/(\d )页</div>', response.text)
# if all_page:
## all_page = all_page.group(1)
## all_page = int(all_page)
# for page_num in range(2, all_page 1):
# page_url = response.url.replace('page=1', 'page={}'.format(page_num))
# yield Request(page_url, self.parse_tweet, dont_filter=True, meta=response.meta)
"""
解析本页的数据
"""
# selector = Selector(response)
# text1 = ";".join(selector.xpath('body/div[@class="c"]//text()').extract()) # 获取标签里的所有text()
# print(text1)
#text = response.body.decode(response.encoding)
text = response.text
#text = text.unescape(text)
html = etree.HTML(text)
#获取script的内容,获得的结果是str类型
text = html.xpath('//script/text()')[16] #只保留最后一个script中的内容
data_html = etree.HTML(text)
print(text)
tweet_nodes = data_html.xpath('//div[@class="WB_info"]/a/text()')
print(tweet_nodes)
# for tweet_node in tweet_nodes:
# try:
# tweet_item = TweetsItem()
# tweet_item['crawl_time'] = int(time.time())
# tweet_repost_url = tweet_node.xpath('.//a[contains(text(),"转发[")]/@href')[0]
# user_tweet_id = re.search(r'/repost/(.*?)\?uid=(\d )', tweet_repost_url)
# tweet_item['weibo_url'] = 'https://weibo.com/{}/{}'.format(user_tweet_id.group(2),
# user_tweet_id.group(1))
# tweet_item['user_id'] = user_tweet_id.group(2)
# tweet_item['_id'] = '{}_{}'.format(user_tweet_id.group(2), user_tweet_id.group(1))
# create_time_info_node = tweet_node.xpath('.//span[@class="ct"]')[-1]
# create_time_info = create_time_info_node.xpath('string(.)')
# if "来自" in create_time_info:
# tweet_item['created_at'] = time_fix(create_time_info.split('来自')[0].strip())
# tweet_item['tool'] = create_time_info.split('来自')[1].strip()
# else:
# tweet_item['created_at'] = time_fix(create_time_info.strip())
#
# like_num = tweet_node.xpath('.//a[contains(text(),"赞[")]/text()')[-1]
# tweet_item['like_num'] = int(re.search('\d ', like_num).group())
#
# repost_num = tweet_node.xpath('.//a[contains(text(),"转发[")]/text()')[-1]
# tweet_item['repost_num'] = int(re.search('\d ', repost_num).group())
#
# comment_num = tweet_node.xpath(
# './/a[contains(text(),"评论[") and not(contains(text(),"原文"))]/text()')[-1]
# tweet_item['comment_num'] = int(re.search('\d ', comment_num).group())
#
# images = tweet_node.xpath('.//img[@alt="图片"]/@src')
# if images:
# tweet_item['image_url'] = images[0]
#
# videos = tweet_node.xpath('.//a[contains(@href,"https://m.weibo.cn/s/video/show?object_id=")]/@href')
# if videos:
# tweet_item['video_url'] = videos[0]
#
# map_node = tweet_node.xpath('.//a[contains(text(),"显示地图")]')
# if map_node:
# map_node = map_node[0]
# map_node_url = map_node.xpath('./@href')[0]
# map_info = re.search(r'xy=(.*?)&', map_node_url).group(1)
# tweet_item['location_map_info'] = map_info
#
# repost_node = tweet_node.xpath('.//a[contains(text(),"原文评论[")]/@href')
# if repost_node:
# tweet_item['origin_weibo'] = repost_node[0]
#
# # 检测由没有阅读全文:
# all_content_link = tweet_node.xpath('.//a[text()="全文" and contains(@href,"ckAll=1")]')
# if all_content_link:
# all_content_url = self.base_url all_content_link[0].xpath('./@href')[0]
# yield Request(all_content_url, callback=self.parse_all_content, meta={'item': tweet_item},
# priority=1)
#
# else:
# tweet_html = etree.tostring(tweet_node, encoding='unicode')
# tweet_item['content'] = extract_weibo_content(tweet_html)
# yield tweet_item
#
## # 抓取该微博的评论信息
## comment_url = self.base_url '/comment/' tweet_item['weibo_url'].split('/')[-1] '?page=1'
## yield Request(url=comment_url, callback=self.parse_comment, meta={'weibo_url': tweet_item['weibo_url']})
#
# except Exception as e:
# self.logger.error(e)
def parse_information(self, response):
""" 抓取个人信息 """
information_item = InformationItem()
information_item['crawl_time'] = int(time.time())
selector = Selector(response)
information_item['_id'] = re.findall('(\d )/info', response.url)[0]
text1 = ";".join(selector.xpath('body/div[@class="c"]//text()').extract()) # 获取标签里的所有text()
print(information_item['_id'] )
print(text1)
nick_name = re.findall('昵称;?[::]?(.*?);', text1)
gender = re.findall('性别;?[::]?(.*?);', text1)
place = re.findall('地区;?[::]?(.*?);', text1)
briefIntroduction = re.findall('简介;?[::]?(.*?);', text1)
birthday = re.findall('生日;?[::]?(.*?);', text1)
sex_orientation = re.findall('性取向;?[::]?(.*?);', text1)
sentiment = re.findall('感情状况;?[::]?(.*?);', text1)
vip_level = re.findall('会员等级;?[::]?(.*?);', text1)
authentication = re.findall('认证;?[::]?(.*?);', text1)
labels = re.findall('标签;?[::]?(.*?)更多>>', text1)
if nick_name and nick_name[0]:
information_item["nick_name"] = nick_name[0].replace(u"\xa0", "")
if gender and gender[0]:
information_item["gender"] = gender[0].replace(u"\xa0", "")
if place and place[0]:
place = place[0].replace(u"\xa0", "").split(" ")
information_item["province"] = place[0]
if len(place) > 1:
information_item["city"] = place[1]
if briefIntroduction and briefIntroduction[0]:
information_item["brief_introduction"] = briefIntroduction[0].replace(u"\xa0", "")
if birthday and birthday[0]:
information_item['birthday'] = birthday[0]
if sex_orientation and sex_orientation[0]:
if sex_orientation[0].replace(u"\xa0", "") == gender[0]:
information_item["sex_orientation"] = "同性恋"
else:
information_item["sex_orientation"] = "异性恋"
if sentiment and sentiment[0]:
information_item["sentiment"] = sentiment[0].replace(u"\xa0", "")
if vip_level and vip_level[0]:
information_item["vip_level"] = vip_level[0].replace(u"\xa0", "")
if authentication and authentication[0]:
information_item["authentication"] = authentication[0].replace(u"\xa0", "")
if labels and labels[0]:
information_item["labels"] = labels[0].replace(u"\xa0", ",").replace(';', '').strip(',')
request_meta = response.meta
request_meta['item'] = information_item
yield Request(self.base_url '/u/{}'.format(information_item['_id']),
callback=self.parse_further_information,
meta=request_meta, dont_filter=True, priority=1)
def parse_further_information(self, response):
text = response.text
information_item = response.meta['item']
tweets_num = re.findall('微博\[(\d )\]', text)
if tweets_num:
information_item['tweets_num'] = int(tweets_num[0])
follows_num = re.findall('关注\[(\d )\]', text)
if follows_num:
information_item['follows_num'] = int(follows_num[0])
fans_num = re.findall('粉丝\[(\d )\]', text)
if fans_num:
information_item['fans_num'] = int(fans_num[0])
yield information_item
# 获取该用户微博
yield Request(url=self.base_url '/{}/profile?page=1'.format(information_item['_id']),
callback=self.parse_tweet,
priority=1)
# 获取关注列表
yield Request(url=self.base_url '/{}/follow?page=1'.format(information_item['_id']),
callback=self.parse_follow,
dont_filter=True)
# 获取粉丝列表
yield Request(url=self.base_url '/{}/fans?page=1'.format(information_item['_id']),
callback=self.parse_fans,
dont_filter=True)
def parse_tweet(self, response):
if response.url.endswith('page=1'):
# 如果是第1页,一次性获取后面的所有页
all_page = re.search(r'/> 1/(\d )页</div>', response.text)
if all_page:
all_page = all_page.group(1)
all_page = int(all_page)
for page_num in range(2, all_page 1):
page_url = response.url.replace('page=1', 'page={}'.format(page_num))
yield Request(page_url, self.parse_tweet, dont_filter=True, meta=response.meta)
"""
解析本页的数据
"""
tree_node = etree.HTML(response.body)
tweet_nodes = tree_node.xpath('//div[@class="c" and @id]')
for tweet_node in tweet_nodes:
try:
tweet_item = TweetsItem()
tweet_item['crawl_time'] = int(time.time())
tweet_repost_url = tweet_node.xpath('.//a[contains(text(),"转发[")]/@href')[0]
user_tweet_id = re.search(r'/repost/(.*?)\?uid=(\d )', tweet_repost_url)
tweet_item['weibo_url'] = 'https://weibo.com/{}/{}'.format(user_tweet_id.group(2),
user_tweet_id.group(1))
tweet_item['user_id'] = user_tweet_id.group(2)
tweet_item['_id'] = '{}_{}'.format(user_tweet_id.group(2), user_tweet_id.group(1))
create_time_info_node = tweet_node.xpath('.//span[@class="ct"]')[-1]
create_time_info = create_time_info_node.xpath('string(.)')
if "来自" in create_time_info:
tweet_item['created_at'] = time_fix(create_time_info.split('来自')[0].strip())
tweet_item['tool'] = create_time_info.split('来自')[1].strip()
else:
tweet_item['created_at'] = time_fix(create_time_info.strip())
like_num = tweet_node.xpath('.//a[contains(text(),"赞[")]/text()')[-1]
tweet_item['like_num'] = int(re.search('\d ', like_num).group())
repost_num = tweet_node.xpath('.//a[contains(text(),"转发[")]/text()')[-1]
tweet_item['repost_num'] = int(re.search('\d ', repost_num).group())
comment_num = tweet_node.xpath(
'.//a[contains(text(),"评论[") and not(contains(text(),"原文"))]/text()')[-1]
tweet_item['comment_num'] = int(re.search('\d ', comment_num).group())
images = tweet_node.xpath('.//img[@alt="图片"]/@src')
if images:
tweet_item['image_url'] = images[0]
videos = tweet_node.xpath('.//a[contains(@href,"https://m.weibo.cn/s/video/show?object_id=")]/@href')
if videos:
tweet_item['video_url'] = videos[0]
map_node = tweet_node.xpath('.//a[contains(text(),"显示地图")]')
if map_node:
map_node = map_node[0]
map_node_url = map_node.xpath('./@href')[0]
map_info = re.search(r'xy=(.*?)&', map_node_url).group(1)
tweet_item['location_map_info'] = map_info
repost_node = tweet_node.xpath('.//a[contains(text(),"原文评论[")]/@href')
if repost_node:
tweet_item['origin_weibo'] = repost_node[0]
# 检测由没有阅读全文:
all_content_link = tweet_node.xpath('.//a[text()="全文" and contains(@href,"ckAll=1")]')
if all_content_link:
all_content_url = self.base_url all_content_link[0].xpath('./@href')[0]
yield Request(all_content_url, callback=self.parse_all_content, meta={'item': tweet_item},
priority=1)
else:
tweet_html = etree.tostring(tweet_node, encoding='unicode')
tweet_item['content'] = extract_weibo_content(tweet_html)
yield tweet_item
# 抓取该微博的评论信息
comment_url = self.base_url '/comment/' tweet_item['weibo_url'].split('/')[-1] '?page=1'
yield Request(url=comment_url, callback=self.parse_comment, meta={'weibo_url': tweet_item['weibo_url']})
except Exception as e:
self.logger.error(e)
def parse_all_content(self, response):
# 有阅读全文的情况,获取全文
tree_node = etree.HTML(response.body)
tweet_item = response.meta['item']
content_node = tree_node.xpath('//*[@id="M_"]/div[1]')[0]
tweet_html = etree.tostring(content_node, encoding='unicode')
tweet_item['content'] = extract_weibo_content(tweet_html)
yield tweet_item
def parse_follow(self, response):
"""
抓取关注列表
"""
# 如果是第1页,一次性获取后面的所有页
if response.url.endswith('page=1'):
all_page = re.search(r'/> 1/(\d )页</div>', response.text)
if all_page:
all_page = all_page.group(1)
all_page = int(all_page)
for page_num in range(2, all_page 1):
page_url = response.url.replace('page=1', 'page={}'.format(page_num))
yield Request(page_url, self.parse_follow, dont_filter=True, meta=response.meta)
selector = Selector(response)
urls = selector.xpath('//a[text()="关注他" or text()="关注她" or text()="取消关注"]/@href').extract()
uids = re.findall('uid=(\d )', ";".join(urls), re.S)
ID = re.findall('(\d )/follow', response.url)[0]
for uid in uids:
relationships_item = RelationshipsItem()
relationships_item['crawl_time'] = int(time.time())
relationships_item["fan_id"] = ID
relationships_item["followed_id"] = uid
relationships_item["_id"] = ID '-' uid
yield relationships_item
def parse_fans(self, response):
"""
抓取粉丝列表
"""
# 如果是第1页,一次性获取后面的所有页
if response.url.endswith('page=1'):
all_page = re.search(r'/> 1/(\d )页</div>', response.text)
if all_page:
all_page = all_page.group(1)
all_page = int(all_page)
for page_num in range(2, all_page 1):
page_url = response.url.replace('page=1', 'page={}'.format(page_num))
yield Request(page_url, self.parse_fans, dont_filter=True, meta=response.meta)
selector = Selector(response)
urls = selector.xpath('//a[text()="关注他" or text()="关注她" or text()="移除"]/@href').extract()
uids = re.findall('uid=(\d )', ";".join(urls), re.S)
ID = re.findall('(\d )/fans', response.url)[0]
for uid in uids:
relationships_item = RelationshipsItem()
relationships_item['crawl_time'] = int(time.time())
relationships_item["fan_id"] = uid
relationships_item["followed_id"] = ID
relationships_item["_id"] = uid '-' ID
yield relationships_item
def parse_comment(self, response):
# 如果是第1页,一次性获取后面的所有页
if response.url.endswith('page=1'):
all_page = re.search(r'/> 1/(\d )页</div>', response.text)
if all_page:
all_page = all_page.group(1)
all_page = int(all_page)
for page_num in range(2, all_page 1):
page_url = response.url.replace('page=1', 'page={}'.format(page_num))
yield Request(page_url, self.parse_comment, dont_filter=True, meta=response.meta)
tree_node = etree.HTML(response.body)
comment_nodes = tree_node.xpath('//div[@class="c" and contains(@id,"C_")]')
for comment_node in comment_nodes:
comment_user_url = comment_node.xpath('.//a[contains(@href,"/u/")]/@href')
if not comment_user_url:
continue
comment_item = CommentItem()
comment_item['crawl_time'] = int(time.time())
comment_item['weibo_url'] = response.meta['weibo_url']
comment_item['comment_user_id'] = re.search(r'/u/(\d )', comment_user_url[0]).group(1)
comment_item['content'] = extract_comment_content(etree.tostring(comment_node, encoding='unicode'))
comment_item['_id'] = comment_node.xpath('./@id')[0]
created_at_info = comment_node.xpath('.//span[@class="ct"]/text()')[0]
like_num = comment_node.xpath('.//a[contains(text(),"赞[")]/text()')[-1]
comment_item['like_num'] = int(re.search('\d ', like_num).group())
comment_item['created_at'] = time_fix(created_at_info.split('\xa0')[0])
yield comment_item
if __name__ == "__main__":
process = CrawlerProcess(get_project_settings())
process.crawl('weibo_spider')
process.start()
相关软件
小贴士
感谢您为本站写下的评论,您的评论对其它用户来说具有重要的参考价值,所以请认真填写。
- 类似“顶”、“沙发”之类没有营养的文字,对勤劳贡献的楼主来说是令人沮丧的反馈信息。
- 相信您也不想看到一排文字/表情墙,所以请不要反馈意义不大的重复字符,也请尽量不要纯表情的回复。
- 提问之前请再仔细看一遍楼主的说明,或许是您遗漏了。
- 请勿到处挖坑绊人、招贴广告。既占空间让人厌烦,又没人会搭理,于人于己都无利。
关于好例子网
本站旨在为广大IT学习爱好者提供一个非营利性互相学习交流分享平台。本站所有资源都可以被免费获取学习研究。本站资源来自网友分享,对搜索内容的合法性不具有预见性、识别性、控制性,仅供学习研究,请务必在下载后24小时内给予删除,不得用于其他任何用途,否则后果自负。基于互联网的特殊性,平台无法对用户传输的作品、信息、内容的权属或合法性、安全性、合规性、真实性、科学性、完整权、有效性等进行实质审查;无论平台是否已进行审查,用户均应自行承担因其传输的作品、信息、内容而可能或已经产生的侵权或权属纠纷等法律责任。本站所有资源不代表本站的观点或立场,基于网友分享,根据中国法律《信息网络传播权保护条例》第二十二与二十三条之规定,若资源存在侵权或相关问题请联系本站客服人员,点此联系我们。关于更多版权及免责申明参见 版权及免责申明

网友评论
我要评论