
实例介绍
一、俄罗斯方块DQN算法实验报告
1. 网络结构
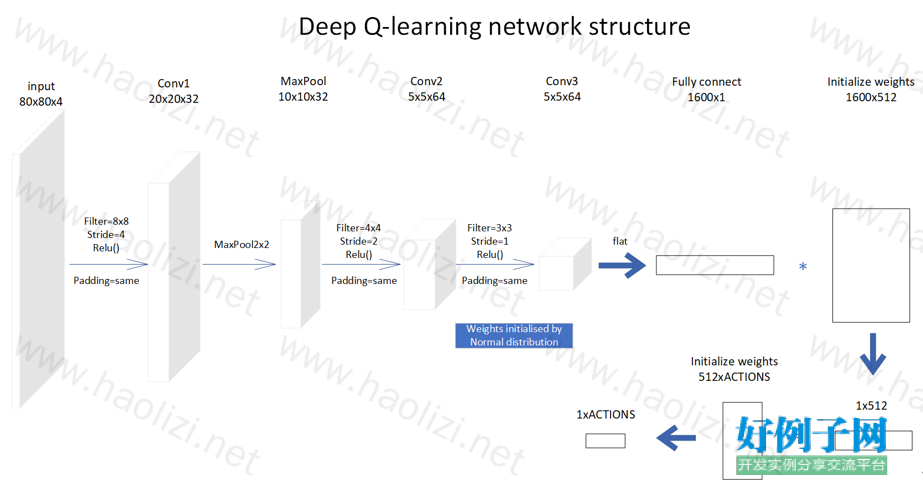
图1 DQN网络结构
2. 超参数
GAMMA = 0.99 # decay rate of past observations 设置增强学习更新公式中的累计折扣因子 OBSERVE = 500. # timesteps to observe before training 设置观察期的迭代次数 EXPLORE = 500. # frames over which to anneal epsilon 设置探索期的观察次数 FINAL_EPSILON = 0.002 # final value of epsilon 设置ε的最终最小值 INITIAL_EPSILON = 10.0 # starting value of epsilon 设置ε的初始值 REPLAY_MEMORY = 5900 # number of previous transitions to remember 设置replay memory的容量 BATCH = 32 # size of mini batch 设置每次网络参数更新世用的样本数目 K = 1 # only select an action every Kth frame, repeat prev for others,设置几帧图像进行一次动作, # K越大让控制台输出的速度变慢,游戏画面速度变快,机器人动作的速度变越迟缓。
ACTIONS = 6 # number of valid actions 游戏动作数
3.实验结果
训练前期的self.score分数很低150左右,EPSILON=1.0,Q_MAX= 2.061341e-02:
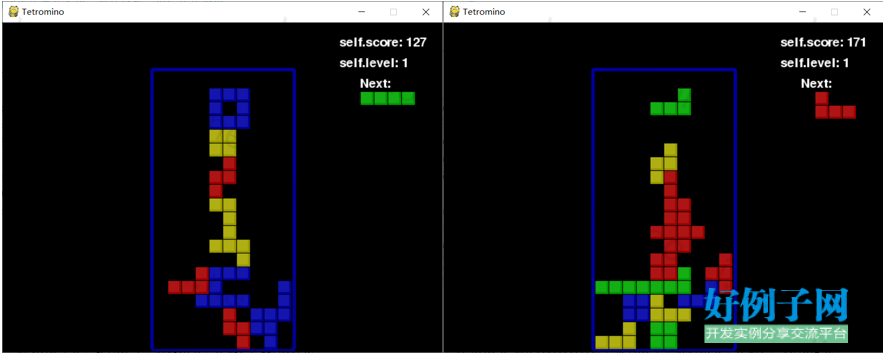
图2 EPSILON=1.0
设置超参数EPSILON=0.05
在1000步迭代之后:
EPSILON固定在0.04999999999999416 Q_MAX = -1.163765e-01
Self.score有明显的提升,但是之后无论训练多久都没有明显提升了。
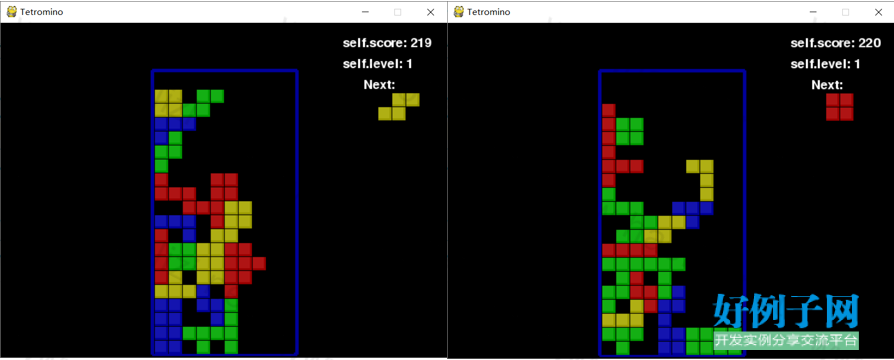
图3 EPSILON=0.05
设置超参数EPSILON= 0.002
在1001步迭代之后:
EPSILON固定在0.000004 Q_MAX = 1.728995e 02
Self.score可以轻松达到200以上。
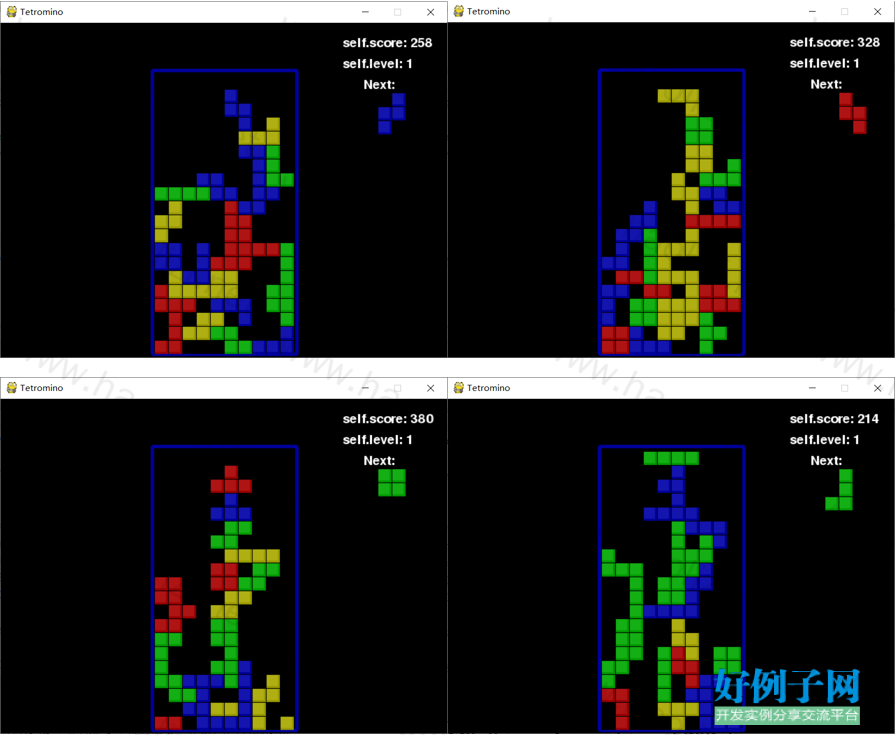
图4 EPSILON=0.000004
设置超参数EPSILON= 0.000001
在1001步迭代之后:
EPSILON固定在-0.001998997999987482 Q_MAX = 1.899879e 03
Self.score可以轻松达到200以上。

图5 EPSILON=-0.002
【核心代码】用DQN来玩俄罗斯方块
tetrix_DQN
├── Wrapped Game Code
│ └── tetris_fun.py
├── deep_q_network.py
├── logs_tetris
│ ├── hidden.txt
│ └── readout.txt
└── saved_networks
├── tetris-dqn-10000.data-00000-of-00001
├── tetris-dqn-10000.index
├── tetris-dqn-10000.meta
└── tetris-dqn-31660000
3 directories, 8 files
相关软件
小贴士
感谢您为本站写下的评论,您的评论对其它用户来说具有重要的参考价值,所以请认真填写。
- 类似“顶”、“沙发”之类没有营养的文字,对勤劳贡献的楼主来说是令人沮丧的反馈信息。
- 相信您也不想看到一排文字/表情墙,所以请不要反馈意义不大的重复字符,也请尽量不要纯表情的回复。
- 提问之前请再仔细看一遍楼主的说明,或许是您遗漏了。
- 请勿到处挖坑绊人、招贴广告。既占空间让人厌烦,又没人会搭理,于人于己都无利。
关于好例子网
本站旨在为广大IT学习爱好者提供一个非营利性互相学习交流分享平台。本站所有资源都可以被免费获取学习研究。本站资源来自网友分享,对搜索内容的合法性不具有预见性、识别性、控制性,仅供学习研究,请务必在下载后24小时内给予删除,不得用于其他任何用途,否则后果自负。基于互联网的特殊性,平台无法对用户传输的作品、信息、内容的权属或合法性、安全性、合规性、真实性、科学性、完整权、有效性等进行实质审查;无论平台是否已进行审查,用户均应自行承担因其传输的作品、信息、内容而可能或已经产生的侵权或权属纠纷等法律责任。本站所有资源不代表本站的观点或立场,基于网友分享,根据中国法律《信息网络传播权保护条例》第二十二与二十三条之规定,若资源存在侵权或相关问题请联系本站客服人员,点此联系我们。关于更多版权及免责申明参见 版权及免责申明

网友评论
我要评论