
实例介绍
【实例简介】
主要实现了通过HtmlParser 实现网页源文件的抓取以及分析,示例中包含了常用的几种操作,更多内容须大家一起完善,虽然本项目是用winform编写,但是其中的代码可以直接copy到web项目中 使用(已做过测试)。
asp.net采集网分析网页用它即可。
另注:需要添加这些引用(项目文件中已包含Winista.HtmlParser.dll的引用)
using Winista.Text.HtmlParser; using Winista.Text.HtmlParser.Filters; using Winista.Text.HtmlParser.Util; using Winista.Text.HtmlParser.Tags;
【实例截图】
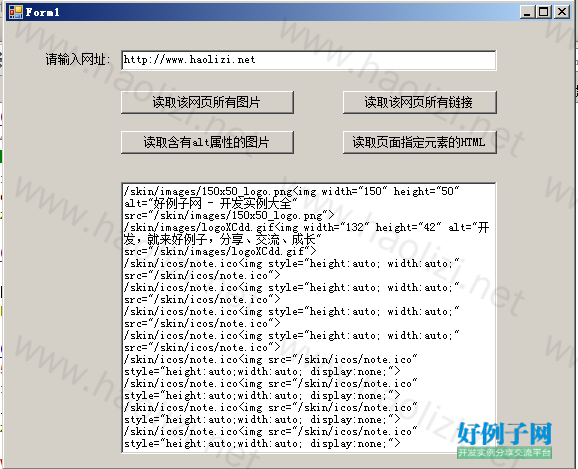
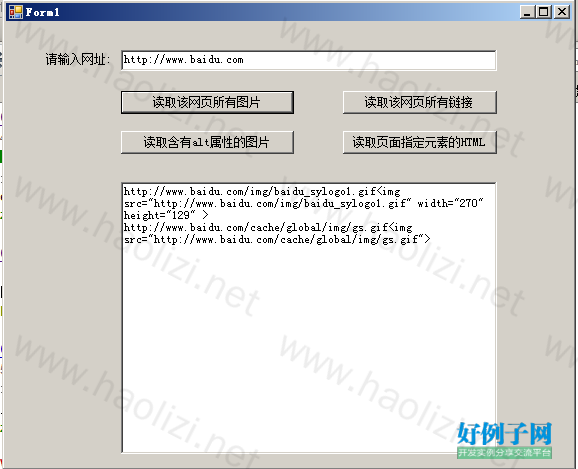

【核心代码】
string strHTML = GetUrl(this.textBox1.Text);
this.textBox2.Text = "";
//this.textBox2.Text = strHTML;
string strTMP = "";
Parser parser = Parser.CreateParser(strHTML, "gb2312");
AndFilter andimg = new AndFilter();
andimg.Predicates = new NodeFilter[] { new NodeClassFilter(typeof(ImageTag)) };
NodeList imglist = parser.ExtractAllNodesThatMatch(andimg);
if (imglist.Count > 0)
{
for (int j = 0; j < imglist.Count; j )
{
ImageTag img = (ImageTag)imglist[j];
strTMP = (img.GetAttribute("src")).ToString() img.ToHtml() "\r\n";
}
}
this.textBox2.Text = strTMP;
标签: HtmlParser 采集
相关软件
网友评论
小贴士
感谢您为本站写下的评论,您的评论对其它用户来说具有重要的参考价值,所以请认真填写。
- 类似“顶”、“沙发”之类没有营养的文字,对勤劳贡献的楼主来说是令人沮丧的反馈信息。
- 相信您也不想看到一排文字/表情墙,所以请不要反馈意义不大的重复字符,也请尽量不要纯表情的回复。
- 提问之前请再仔细看一遍楼主的说明,或许是您遗漏了。
- 请勿到处挖坑绊人、招贴广告。既占空间让人厌烦,又没人会搭理,于人于己都无利。
关于好例子网
本站旨在为广大IT学习爱好者提供一个非营利性互相学习交流分享平台。本站所有资源都可以被免费获取学习研究。本站资源来自网友分享,对搜索内容的合法性不具有预见性、识别性、控制性,仅供学习研究,请务必在下载后24小时内给予删除,不得用于其他任何用途,否则后果自负。基于互联网的特殊性,平台无法对用户传输的作品、信息、内容的权属或合法性、安全性、合规性、真实性、科学性、完整权、有效性等进行实质审查;无论平台是否已进行审查,用户均应自行承担因其传输的作品、信息、内容而可能或已经产生的侵权或权属纠纷等法律责任。本站所有资源不代表本站的观点或立场,基于网友分享,根据中国法律《信息网络传播权保护条例》第二十二与二十三条之规定,若资源存在侵权或相关问题请联系本站客服人员,点此联系我们。关于更多版权及免责申明参见 版权及免责申明

支持(0) 盖楼(回复)
支持(0) 盖楼(回复)