
实例介绍
【实例简介】
【实例截图】
【核心代码】# 利用lightgbm做learning to rank 排序,主要包括:
- 数据预处理
- 模型训练
- 模型决策可视化
- 预测
- ndcg评估
- 特征重要度
- SHAP特征贡献度解释
- 样本的叶结点输出
(要求安装lightgbm、graphviz、shap等)
## 一.data format (raw data -> (feats.txt, group.txt))
###### python lgb_ltr.py -process
##### 1.raw_train.txt
0 qid:10002 1:0.007477 2:0.000000 ... 45:0.000000 46:0.007042 #docid = GX008-86-4444840 inc = 1 prob = 0.086622
0 qid:10002 1:0.603738 2:0.000000 ... 45:0.333333 46:1.000000 #docid = GX037-06-11625428 inc = 0.0031586555555558 prob = 0.0897452
...
##### 2.feats.txt:
0 1:0.007477 2:0.000000 ... 45:0.000000 46:0.007042
0 1:0.603738 2:0.000000 ... 45:0.333333 46:1.000000
...
##### 3.group.txt:
8
8
8
8
8
16
8
118
16
8
...
## 二.model train (feats.txt, group.txt) -> train -> model.mod
###### python lgb_ltr.py -train
train params = {
'task': 'train', # 执行的任务类型
'boosting_type': 'gbrt', # 基学习器
'objective': 'lambdarank', # 排序任务(目标函数)
'metric': 'ndcg', # 度量的指标(评估函数)
'max_position': 10, # @NDCG 位置优化
'metric_freq': 1, # 每隔多少次输出一次度量结果
'train_metric': True, # 训练时就输出度量结果
'ndcg_at': [10],
'max_bin': 255, # 一个整数,表示最大的桶的数量。默认值为 255。lightgbm 会根据它来自动压缩内存。如max_bin=255 时,则lightgbm 将使用uint8 来表示特征的每一个值。
'num_iterations': 200, # 迭代次数,即生成的树的棵数
'learning_rate': 0.01, # 学习率
'num_leaves': 31, # 叶子数
'max_depth':6,
'tree_learner': 'serial', # 用于并行学习,‘serial’: 单台机器的tree learner
'min_data_in_leaf': 30, # 一个叶子节点上包含的最少样本数量
'verbose': 2 # 显示训练时的信息
}
- docs:7796
- groups:380
- consume time : 4 seconds
- training's ndcg@10: 0.940891
##### 1.model.mod(model的格式在data/model/mode.mod)
训练时的输出:
- [LightGBM] [Info] Total Bins 9171
- [LightGBM] [Info] Number of data: 7796, number of used features: 40
- [LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 9
- [1] training's ndcg@10: 0.791427
- [LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 12
- [2] training's ndcg@10: 0.828608
- [LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 10
- ...
- ...
- ...
- [198] training's ndcg@10: 0.941018
- [LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 11
- [199] training's ndcg@10: 0.941038
- [LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 11
- [200] training's ndcg@10: 0.940891
- consume time : 4 seconds
## 三.模型决策过程的可视化生成
可指定树的索引进行可视化生成,便于分析决策过程。
###### python lgb_ltr.py -plottree
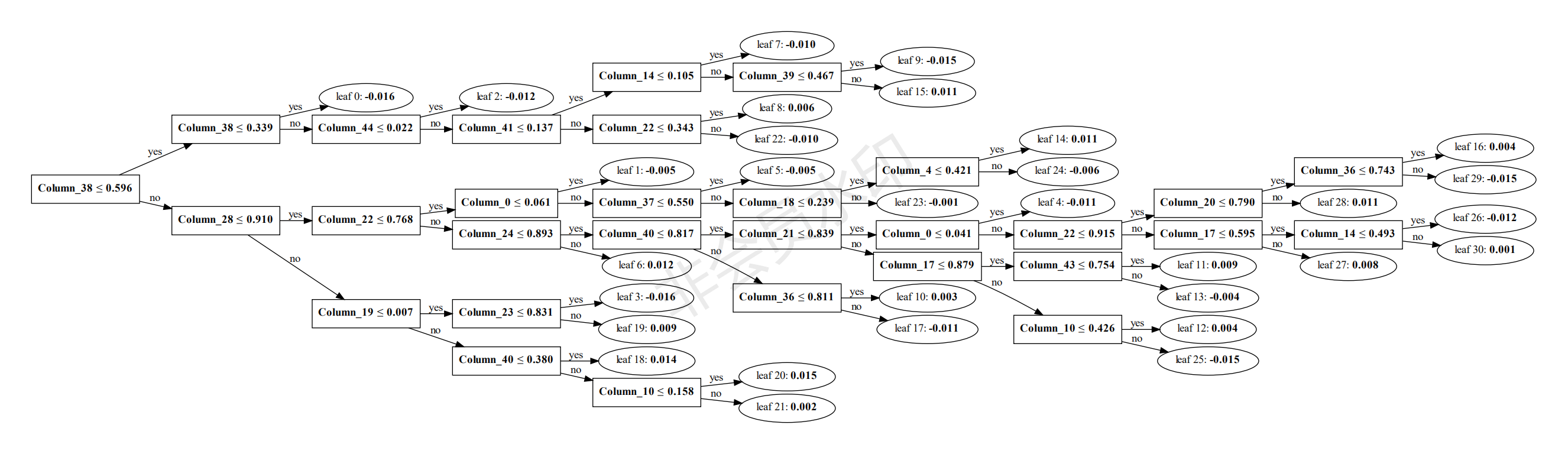
## 四.predict 数据格式如feats.txt,当然可以在每行后面加一个标识(如文档编号,商品编码等)作为排序的输出,这里我直接从test.txt中得到feats与comment作为predict
###### python lgb_ltr.py -predict
##### 1.predict results
- ['docid = GX252-32-5579630 inc = 1 prob = 0.190849'
- 'docid = GX108-43-5342284 inc = 0.188670948386237 prob = 0.103576'
- 'docid = GX039-85-6430259 inc = 1 prob = 0.300191' ...,
- 'docid = GX009-50-15026058 inc = 1 prob = 0.082903'
- 'docid = GX065-08-0661325 inc = 0.012907717401617 prob = 0.0312699'
- 'docid = GX012-13-5603768 inc = 1 prob = 0.0961297']
## 五.validate ndcg 数据来自test.txt(data from test.txt)
###### python lgb_ltr.py -ndcg
all qids average ndcg: 0.761044123343
## 六.features 打印特征重要度(features importance)
###### python lgb_ltr.py -feature
模型中的特征是"Column_number",这里打印重要度时可以映射到真实的特征名,比如本测试用例是46个feature
##### 1.features importance
- feat0name : 228 : 0.038
- feat1name : 22 : 0.0036666666666666666
- feat2name : 27 : 0.0045
- feat3name : 11 : 0.0018333333333333333
- feat4name : 198 : 0.033
- feat10name : 160 : 0.02666666666666667
- ...
- ...
- ...
- feat37name : 188 : 0.03133333333333333
- feat38name : 434 : 0.07233333333333333
- feat39name : 286 : 0.04766666666666667
- feat40name : 169 : 0.028166666666666666
- feat41name : 348 : 0.058
- feat43name : 304 : 0.050666666666666665
- feat44name : 283 : 0.04716666666666667
- feat45name : 220 : 0.03666666666666667
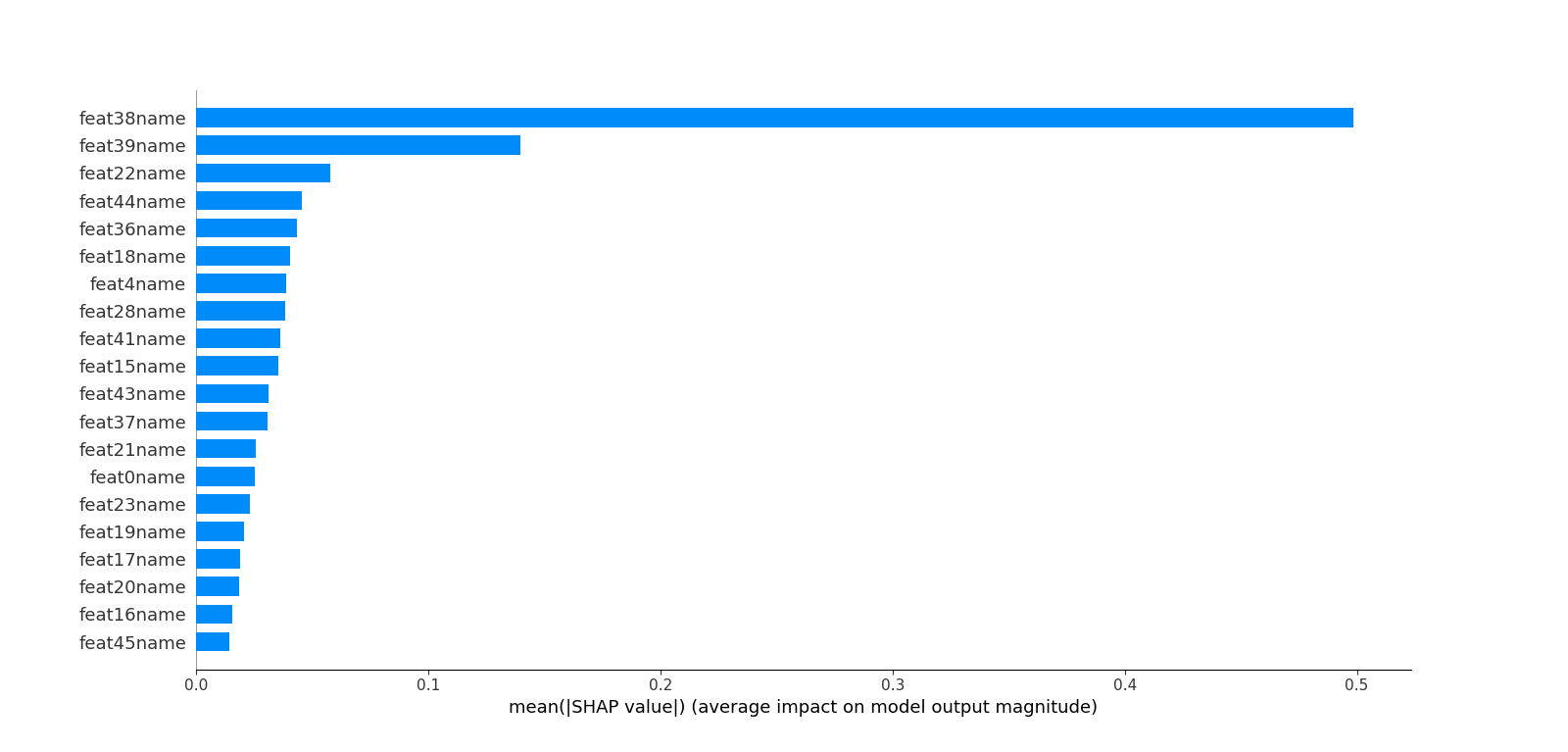
## 七.利用SHAP值解析模型中特征重要度
###### python lgb_ltr.py -shap
这里不同于六中特征重要度的计算,而是利用博弈论的方法--SHAP(SHapley Additive exPlanations)来解析模型。
利用SHAP可以进行特征总体分析、多维特征交叉分析以及单特征分析等。
##### 1.总体分析
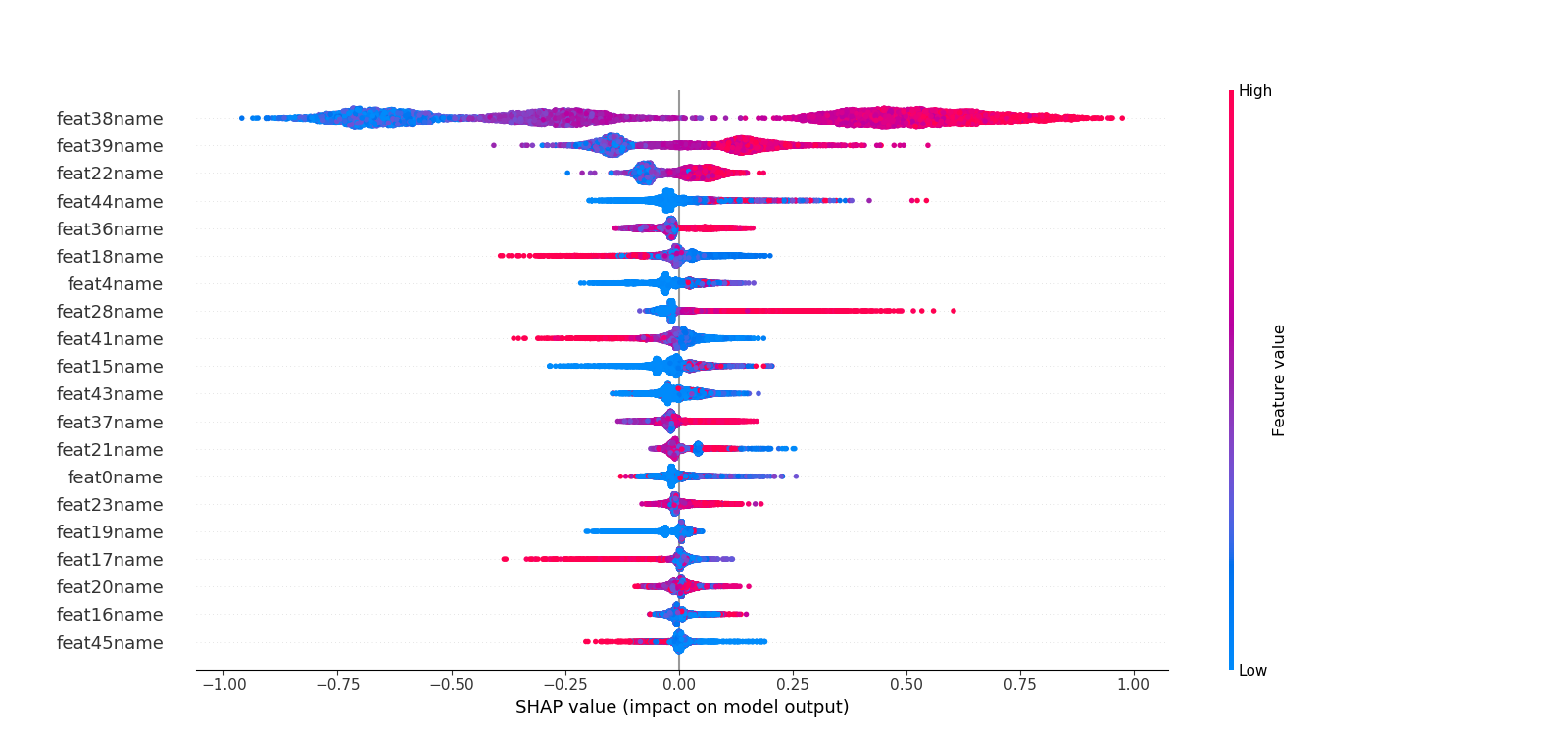
##### 2.多维特征交叉分析
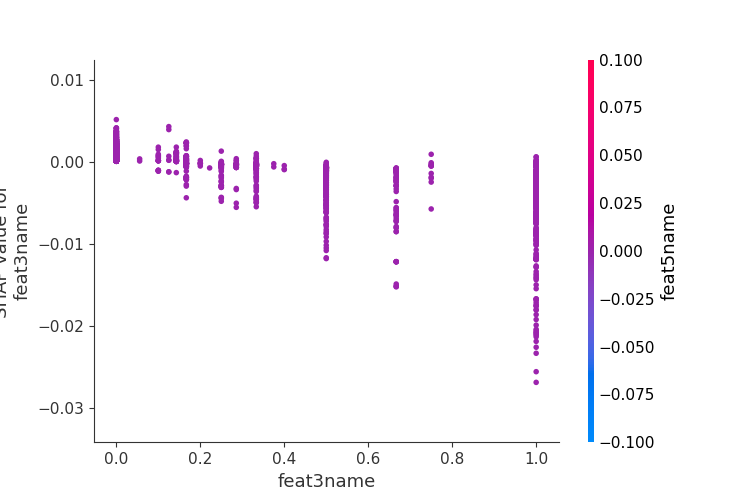
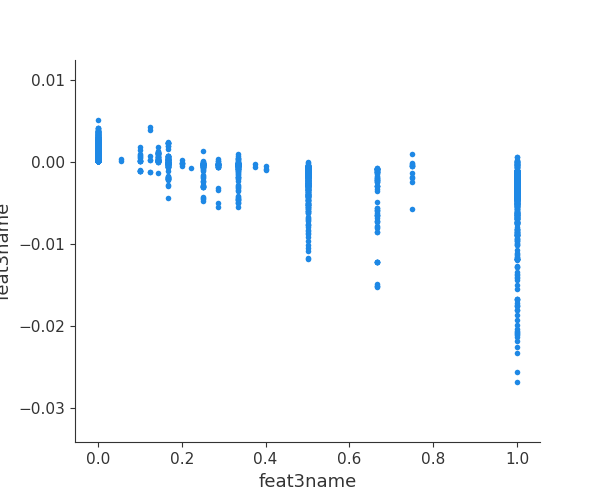
##### 3.单特征分析
## 八.利用模型得到样本叶结点的one-hot表示,可以用于像gbdt lr这种模型的训练
###### python lgb_ltr.py -leaf
这里测试用例是test/leaf.txt 5个样本
[
- [ 0. 1. 0. ..., 0. 0. 1.]
- [ 1. 0. 0. ..., 0. 0. 0.]
- [ 0. 0. 1. ..., 0. 0. 1.]
- [ 0. 1. 0. ..., 0. 1. 0.]
- [ 0. 0. 0. ..., 1. 0. 0.]
]
## 九.REFERENCES
https://github.com/microsoft/LightGBM
https://github.com/jma127/pyltr
https://github.com/slundberg/shap
【实例截图】
【核心代码】# 利用lightgbm做learning to rank 排序,主要包括:
- 数据预处理
- 模型训练
- 模型决策可视化
- 预测
- ndcg评估
- 特征重要度
- SHAP特征贡献度解释
- 样本的叶结点输出
(要求安装lightgbm、graphviz、shap等)
## 一.data format (raw data -> (feats.txt, group.txt))
###### python lgb_ltr.py -process
##### 1.raw_train.txt
0 qid:10002 1:0.007477 2:0.000000 ... 45:0.000000 46:0.007042 #docid = GX008-86-4444840 inc = 1 prob = 0.086622
0 qid:10002 1:0.603738 2:0.000000 ... 45:0.333333 46:1.000000 #docid = GX037-06-11625428 inc = 0.0031586555555558 prob = 0.0897452
...
##### 2.feats.txt:
0 1:0.007477 2:0.000000 ... 45:0.000000 46:0.007042
0 1:0.603738 2:0.000000 ... 45:0.333333 46:1.000000
...
##### 3.group.txt:
8
8
8
8
8
16
8
118
16
8
...
## 二.model train (feats.txt, group.txt) -> train -> model.mod
###### python lgb_ltr.py -train
train params = {
'task': 'train', # 执行的任务类型
'boosting_type': 'gbrt', # 基学习器
'objective': 'lambdarank', # 排序任务(目标函数)
'metric': 'ndcg', # 度量的指标(评估函数)
'max_position': 10, # @NDCG 位置优化
'metric_freq': 1, # 每隔多少次输出一次度量结果
'train_metric': True, # 训练时就输出度量结果
'ndcg_at': [10],
'max_bin': 255, # 一个整数,表示最大的桶的数量。默认值为 255。lightgbm 会根据它来自动压缩内存。如max_bin=255 时,则lightgbm 将使用uint8 来表示特征的每一个值。
'num_iterations': 200, # 迭代次数,即生成的树的棵数
'learning_rate': 0.01, # 学习率
'num_leaves': 31, # 叶子数
'max_depth':6,
'tree_learner': 'serial', # 用于并行学习,‘serial’: 单台机器的tree learner
'min_data_in_leaf': 30, # 一个叶子节点上包含的最少样本数量
'verbose': 2 # 显示训练时的信息
}
- docs:7796
- groups:380
- consume time : 4 seconds
- training's ndcg@10: 0.940891
##### 1.model.mod(model的格式在data/model/mode.mod)
训练时的输出:
- [LightGBM] [Info] Total Bins 9171
- [LightGBM] [Info] Number of data: 7796, number of used features: 40
- [LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 9
- [1] training's ndcg@10: 0.791427
- [LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 12
- [2] training's ndcg@10: 0.828608
- [LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 10
- ...
- ...
- ...
- [198] training's ndcg@10: 0.941018
- [LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 11
- [199] training's ndcg@10: 0.941038
- [LightGBM] [Debug] Trained a tree with leaves = 31 and max_depth = 11
- [200] training's ndcg@10: 0.940891
- consume time : 4 seconds
## 三.模型决策过程的可视化生成
可指定树的索引进行可视化生成,便于分析决策过程。
###### python lgb_ltr.py -plottree

## 四.predict 数据格式如feats.txt,当然可以在每行后面加一个标识(如文档编号,商品编码等)作为排序的输出,这里我直接从test.txt中得到feats与comment作为predict
###### python lgb_ltr.py -predict
##### 1.predict results
- ['docid = GX252-32-5579630 inc = 1 prob = 0.190849'
- 'docid = GX108-43-5342284 inc = 0.188670948386237 prob = 0.103576'
- 'docid = GX039-85-6430259 inc = 1 prob = 0.300191' ...,
- 'docid = GX009-50-15026058 inc = 1 prob = 0.082903'
- 'docid = GX065-08-0661325 inc = 0.012907717401617 prob = 0.0312699'
- 'docid = GX012-13-5603768 inc = 1 prob = 0.0961297']
## 五.validate ndcg 数据来自test.txt(data from test.txt)
###### python lgb_ltr.py -ndcg
all qids average ndcg: 0.761044123343
## 六.features 打印特征重要度(features importance)
###### python lgb_ltr.py -feature
模型中的特征是"Column_number",这里打印重要度时可以映射到真实的特征名,比如本测试用例是46个feature
##### 1.features importance
- feat0name : 228 : 0.038
- feat1name : 22 : 0.0036666666666666666
- feat2name : 27 : 0.0045
- feat3name : 11 : 0.0018333333333333333
- feat4name : 198 : 0.033
- feat10name : 160 : 0.02666666666666667
- ...
- ...
- ...
- feat37name : 188 : 0.03133333333333333
- feat38name : 434 : 0.07233333333333333
- feat39name : 286 : 0.04766666666666667
- feat40name : 169 : 0.028166666666666666
- feat41name : 348 : 0.058
- feat43name : 304 : 0.050666666666666665
- feat44name : 283 : 0.04716666666666667
- feat45name : 220 : 0.03666666666666667
## 七.利用SHAP值解析模型中特征重要度
###### python lgb_ltr.py -shap
这里不同于六中特征重要度的计算,而是利用博弈论的方法--SHAP(SHapley Additive exPlanations)来解析模型。
利用SHAP可以进行特征总体分析、多维特征交叉分析以及单特征分析等。
##### 1.总体分析


##### 2.多维特征交叉分析

##### 3.单特征分析

## 八.利用模型得到样本叶结点的one-hot表示,可以用于像gbdt lr这种模型的训练
###### python lgb_ltr.py -leaf
这里测试用例是test/leaf.txt 5个样本
[
- [ 0. 1. 0. ..., 0. 0. 1.]
- [ 1. 0. 0. ..., 0. 0. 0.]
- [ 0. 0. 1. ..., 0. 0. 1.]
- [ 0. 1. 0. ..., 0. 1. 0.]
- [ 0. 0. 0. ..., 1. 0. 0.]
]
## 九.REFERENCES
https://github.com/microsoft/LightGBM
https://github.com/jma127/pyltr
https://github.com/slundberg/shap
好例子网口号:伸出你的我的手 — 分享!
相关软件
小贴士
感谢您为本站写下的评论,您的评论对其它用户来说具有重要的参考价值,所以请认真填写。
- 类似“顶”、“沙发”之类没有营养的文字,对勤劳贡献的楼主来说是令人沮丧的反馈信息。
- 相信您也不想看到一排文字/表情墙,所以请不要反馈意义不大的重复字符,也请尽量不要纯表情的回复。
- 提问之前请再仔细看一遍楼主的说明,或许是您遗漏了。
- 请勿到处挖坑绊人、招贴广告。既占空间让人厌烦,又没人会搭理,于人于己都无利。
关于好例子网
本站旨在为广大IT学习爱好者提供一个非营利性互相学习交流分享平台。本站所有资源都可以被免费获取学习研究。本站资源来自网友分享,对搜索内容的合法性不具有预见性、识别性、控制性,仅供学习研究,请务必在下载后24小时内给予删除,不得用于其他任何用途,否则后果自负。基于互联网的特殊性,平台无法对用户传输的作品、信息、内容的权属或合法性、安全性、合规性、真实性、科学性、完整权、有效性等进行实质审查;无论平台是否已进行审查,用户均应自行承担因其传输的作品、信息、内容而可能或已经产生的侵权或权属纠纷等法律责任。本站所有资源不代表本站的观点或立场,基于网友分享,根据中国法律《信息网络传播权保护条例》第二十二与二十三条之规定,若资源存在侵权或相关问题请联系本站客服人员,点此联系我们。关于更多版权及免责申明参见 版权及免责申明

网友评论
我要评论