
实例介绍
【实例简介】可以设置的ip数量爬取
运行前需要安装 bs4模块 以及 requests模块
下载地址分别为:
https://pypi.python.org/packages/10/ed/7e8b97591f6f456174139ec089c769f89a94a1a4025fe967691de971f314/bs4-0.0.1.tar.gz
https://pypi.python.org/packages/16/09/37b69de7c924d318e51ece1c4ceb679bf93be9d05973bb30c35babd596e2/requests-2.13.0.tar.gz#md5=921ec6b48f2ddafc8bb6160957baf444
下载后安装方法如下(以bs4模块为例):
1.解压bs4-0.0.1.tar.gz文件后,并 在命令行 cd到该目录,输入命令: python setup.py install
2. 回车运行,安装完毕
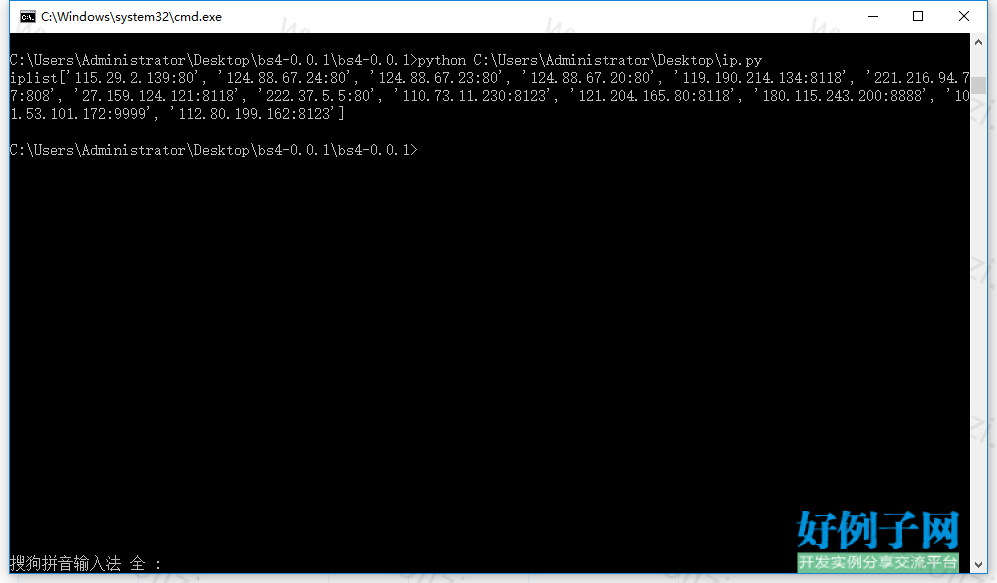
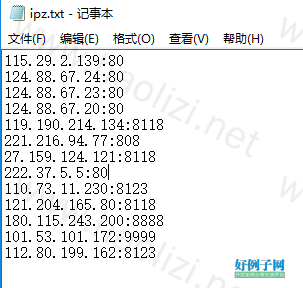
【实例截图】
【核心代码】
import re
from random import choice
import requests
import bs4
url = "http://www.xicidaili.com/"
headers = { "Accept":"text/html,application/xhtml xml,application/xml;",
"Accept-Encoding":"gzip",
"Accept-Language":"zh-CN,zh;q=0.8",
"Referer":"http://www.xicidaili.com/",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36"
}
r = requests.get(url,headers=headers)
soup = bs4.BeautifulSoup(r.text, 'html.parser')
data = soup.table.find_all("td",limit=100) # limit是获取td的个数,这里可以指定获取多少个IP
ip_compile= re.compile(r'<td>(\d \.\d \.\d \.\d )</td>')
port_compile = re.compile(r'<td>(\d )</td>')
ip = re.findall(ip_compile,str(data))
port = re.findall(port_compile,str(data))
ipz = [":".join(i) for i in zip(ip,port)]
print u"代理IP列表:{ip_list}".format(ip_list=ipz)
tmps="\r\n".join(ipz)
if ipz: open("ipz.txt","wb").write(tmps.encode("utf-8"))
小贴士
感谢您为本站写下的评论,您的评论对其它用户来说具有重要的参考价值,所以请认真填写。
- 类似“顶”、“沙发”之类没有营养的文字,对勤劳贡献的楼主来说是令人沮丧的反馈信息。
- 相信您也不想看到一排文字/表情墙,所以请不要反馈意义不大的重复字符,也请尽量不要纯表情的回复。
- 提问之前请再仔细看一遍楼主的说明,或许是您遗漏了。
- 请勿到处挖坑绊人、招贴广告。既占空间让人厌烦,又没人会搭理,于人于己都无利。
关于好例子网
本站旨在为广大IT学习爱好者提供一个非营利性互相学习交流分享平台。本站所有资源都可以被免费获取学习研究。本站资源来自网友分享,对搜索内容的合法性不具有预见性、识别性、控制性,仅供学习研究,请务必在下载后24小时内给予删除,不得用于其他任何用途,否则后果自负。基于互联网的特殊性,平台无法对用户传输的作品、信息、内容的权属或合法性、安全性、合规性、真实性、科学性、完整权、有效性等进行实质审查;无论平台是否已进行审查,用户均应自行承担因其传输的作品、信息、内容而可能或已经产生的侵权或权属纠纷等法律责任。本站所有资源不代表本站的观点或立场,基于网友分享,根据中国法律《信息网络传播权保护条例》第二十二与二十三条之规定,若资源存在侵权或相关问题请联系本站客服人员,点此联系我们。关于更多版权及免责申明参见 版权及免责申明

网友评论
我要评论